"MOVA" --- скрипты для работы со словарями в формате "MOVA"
Предлагаемые скрипты используйте на условиях GNU GPL.
Скрипты используют стандартные утилиты UNIX - grep, sed, fmt, а для работы в консоли еще и groff, less. Они проводят поиск в текстовом файле и выводят найденные строчки в графическую оболочку. Плюсы такого механизма работы:
Обратите внимание на размер оперативной памяти: если памяти достаточно (например, 64 Mb при использовании fvwm2), то повторные вызовы словаря намного быстрее первого, так как текст словаря остается в дисковом кэше и сразу становится доступными по мере надобности (исключается медленное копирование словаря с жесткого диска в оперативную память). Но работа при 32 Mb (при поиске без хеширования) практически невозможна (так как страницы со словарем быстро вытесняются на диск из оперативной памяти - при этом каждый новый запуск поиска включает чтение словаря с жесткого диска, что приводит к 1-2 с ожидания результата, но если начинает работать swap (при работе поиска), то время ожидания становится намного больше).
Сейчас movaTK и movaMTK использует хеширование при поиске слов сначала словарной статьи (опции -W и -B), это позволяет пользоваться словарем (с данными опциями) при меньших размерах ОЗУ. Словари отхешированы по первым двум буквам словарной статьи и хранятся в файле с названием словаря и добавлением к его названию слова ".hash". Цифра идущая за двухбуквенным сочетанием в строчке из файла хеша означает порядковый номер байта на котором кончается блок в котором все словарные статьи начинаются с данного двубуквенного сочетания. Если запросить поиск слова для которого нет хешированного двубуквенного начала, то включается обычный поиск (без использования хеша). К сожалению, маленький (а иначе индексирование не дает выигрыша) индексный файл получается при индексировании по ограниченному числу слов. Если же нужно иметь возможность поиска по всем словам словарной статьи (и, особенно, словосочетаниям), то хеширование не дает никакого выигрыша IMHO.
Основная работа по поиску строк и форматированию выполняется bash
скриптом - mova . В коммандной строке скрипту можно задать опции поиска, слово или последовательность слов для поиска и, в конце, полный путь к файлу словаря, в котором производится поиск. При этом, он будет искать слово сначала словарной строки (опция "-W"), первую часть слова сначала словарной строки (опция "-B"), последовательность слов внутри словарной строки (опция "-S", можно использовать как русско-английский словарь), последовательность символов (включая пробелы) внутри словарной строки (опция "-T"). Затем найденные строки пропускаются через sed фильтр, который добавляет к каждой словарной статье пустую строчку и форматирование по вариантам значения слова. В консоли лучше использовать аналогичные опции со строчными буквами (при этом подключается groff и less фильтры, а невидимые в koi8-r символы транскрипции перекодируются в видимые) см. screenshot
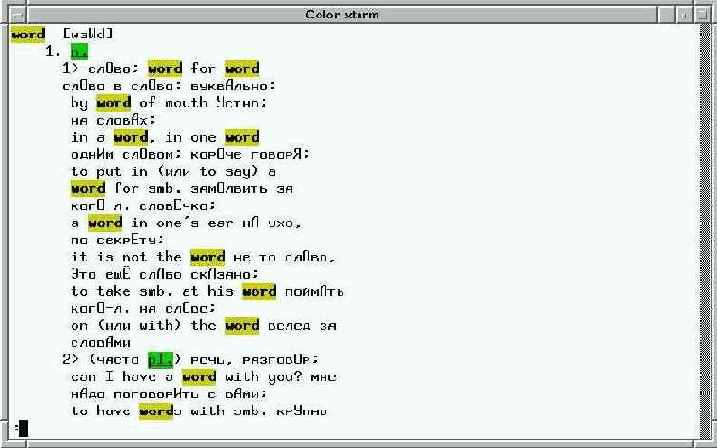
movaTK, см. screenshot
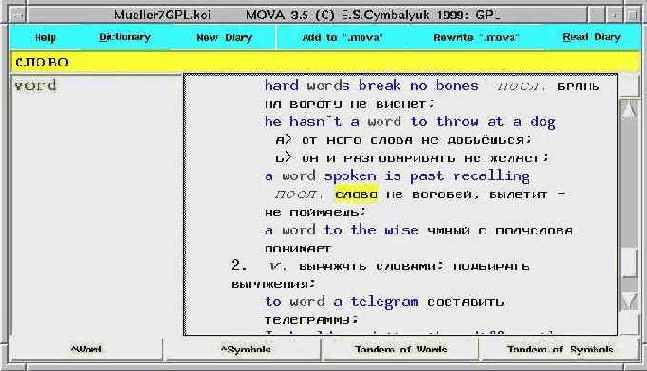
movaMTK использует другой способ вывода информации в окна (он удобнее, если нужно оставить на экране перевод ранее найденых слов, хотя работает медленнее). См. screenshot
movaTK и movaMTK раскрашивают в красный цвет транскрипцию и подставляют соответствующий фонт для символов между квадратными скобками. Голубым отмечаются английские слова, зеленым и наклонным шрифтом - служебные (грамматические еще выделяется жирным шрифтом). Слово или буквы поиска выделяются коричневым цветом. Часть словарной статьи до двух пробелов выделяется шрифтом FONT_FIND (этот же шрифт используется в желтой строчке ввода и для выделения слова в сером окне истории поиска).
Выйти из movaTK и movaMTK можно нажав "Esc"
Над и под скролбаром находятся квадратные кнопочки - с их помощью можно искать выделенное мышкой слово в уже выведенной словарной статье.
Напомню, как работают с этими оболочками. Слово или слова выделяются мышкой (при этом лишние пробелы не мешают). Затем из xterm или встроенной кнопкой (для fvwm2 отредактируйте файл .fvwm2rc в своей директории) запускается соответственный Tcl/Tk скрипт. Например, так
DestroyMenu "Utilities"
AddToMenu "Utilities@utilities-menu.xpm@^white^"
+ "Mueller7%mova_32x22.xpm%" Exec movaTK -W Mueller7GPL.koi&
+ "Mueller7 M%mova_32x32.xpm%" Exec movaMTK -W Mueller7GPL.koi& Оболочками можно пользоваться и без мышки. Для этого введите слово для перевода вручную в верхней (желтой) строке. При этом поиск с опцией "-W" запускается нажатием клавиши "Enter"; "-B" -
"Shift-Enter"; "-S" - "Ctrl-Enter"; а "-T" - "Alt-Enter".
Еще один важный управляющий скрипт: mova_sendTK. С его помощью можно послать выделенную мышкой строчку на перевод в первое открытое окно
movaTK для каждого словаря. Если открытого окна movaTK для
Mueller7GPL.koi нет, то будет запущена новая movaTK для этого словаря. Запускать mova_sendTK нужно с опциями для поиска, аналогичными для movaTK и mova. Если Вы хотите иметь возможность запускать поиск в словаре из любой программы на десктопе нажатием клавиш на клавиатуре, то добавьте в Ваш .fvwm2rc следующие строчки:
# Now some keyboard shortcuts.
#Keys for Mueller's dictionary
Key z A M Exec mova_sendTK -W &
Key В A M Exec mova_sendTK -W &
Key x A M Exec mova_sendTK -B &
Key Ъ A M Exec mova_sendTK -B &
Key a A M Exec mova_sendTK -S &
Key Т A M Exec mova_sendTK -S &
Key s A M Exec mova_sendTK -T &
Key Ш A M Exec mova_sendTK -T &
После перезапуска X-ов Вы получите возможность вызывать поиск выделенного мышкой слова в movaTK нажатием Alt-a (для поиска с опцией -S), Alt-s (для поиска с опцией -T), Alt-z
(для поиска с опцией -W), Alt-x (для поиска с опцией -B). Если клавиатура будет в koi8-r кодировке, то соответствующие клавиши будут работать также. Причем клавиши с Alt будут работать в любом месте десктопа и из окон большинства программ. Если запущенного movaTK нет, то нажатие этих клавиш запустит новый movaTK. Сечас mova_sendTK посылает указание переводить выделенное слово/слова извесным мне словарям (доступным в Интернете в формате "MOVA"). Список словарей для запуска находится в теле скрипта.
Иногда, wish не хочет посылать данные в уже открытую программу и говорит, что у него проблемы с секретностью. Попробуйте выполнить
xauth add :0 . `mcookie`
и затем добавьте в персональный .xserverrc
exec X :0 -auth ~/.Xauthority
и перезапустите X-ы
Словари, скрипты, настроечные файлы и описания размещаются согласно FHS (File Hierarchy Standard) - в /share/dict/, /share/mova/, /share/doc/mova/. При этом существует точка привязки всех используемых директорий (внутри скриптов это переменная DIR=/usr/local/). Точку привязки можно изменить в настроечных файлах - .movarc" или
.movarc_СЛОВАРЬ помещенных в домашнем каталоге или в DIR/share/mova/ или теле скрипта (при отсутствии настроечных файлов). Для инсталяции пакета скопируйте запакованный файл в корневую директорию "/" и выполните команды:
tar -xzf Mueller7GPL.tgz
tar -xzf script_mova.tgz
Для словарей с транскрипцией нужно добавить Sil-IPA шрифты в
XF86Config:
FontPath "/usr/X11R6/lib/fonts/sil_ipa/"
Родной сайт (http://www.sil.org/computing/fonts/encore-ipa.html) Sil-IPA шрифтов имеет еще и набор TrueType фонтов. Данные фонты распространяются под особой Free лицензией и для коммерческого использования нужно договариваться с авторами фонтов отдельно.
Все установки шрифтов и используемый по умолчанию словарь меняются в начале файла Tcl/Tk скриптов: в movaTK и movaMTK:
set FONT_FIND -*-*-bold-r-*-*-17-*-*-*-*-*-koi8-r
set FONT_TEXT -*-*-medium-r-*-*-17-*-*-*-*-*-koi8-r
set FONT_D -*-*-medium-o-*-*-17-*-*-*-*-*-koi8-r
set FONT_DG -*-*-bold-o-*-*-17-*-*-*-*-*-koi8-r
set FONT_IPA -*-silsophiaipa-*-r-*-17-*-*-*-*-*-*-*
set DIR /usr/local/
set DIR_TMP /tmp/
set DIC Mueller7GPL.koi
Можно также сделать отдельный файл настроек в домашнем каталоге с названием
".movarc", тогда будут считываться установки из этого файла. Если при запуске mova или movaTK/movaMTK в коммандной строке не указано название словаря, то по умолчанию будет запускаться поиск в словаре с именем
DIC. Пример соответствующего ".movarc",
-*-*-bold-r-*-*-20-*-*-*-*-*-*-koi8-r
-*-*-medium-r-*-*-20-*-*-*-*-*-koi8-r
-*-*-medium-o-*-*-20-*-*-*-*-*-koi8-r
-*-*-bold-o-*-*-21-*-*-*-*-*-koi8-r
-*-silsophiaipa-*-r-*-20-*-*-*-p-*-*-*
/usr/local/
/tmp/
Mueller7GPL.koi
Для индивидуальной настройки словарей, скажем для словарей европейских языков в ".movarc_СЛОВАРЬ" (где СЛОВАРЬ - имя файла словаря) нужно выставить подходящие фонты для FONT_FIND. Пример соответствующего
".movarc__СЛОВАРЬ",
-*-*-bold-r-*-*-20-*-*-*-*-*-*-1
-*-*-medium-r-*-*-20-*-*-*-*-*-koi8-r
-*-*-medium-o-*-*-20-*-*-*-*-*-koi8-r
-*-*-bold-o-*-*-21-*-*-*-*-*-koi8-r
-*-silsophiaipa-*-r-*-20-*-*-*-p-*-*-*
/usr/local/
/tmp/
И ".movarc" и ".movarc__СЛОВАРЬ" можно положить в директорию с настройками всего пакета - DIR/share/mova/. Они будут использоваться при отсутствии соответствующих файлов в домашней директории.
В самой верхней голубой строчке находятся кнопки:
Help - при нажатии выведится русский текст с краткой инструкцией по использованию оболочек.
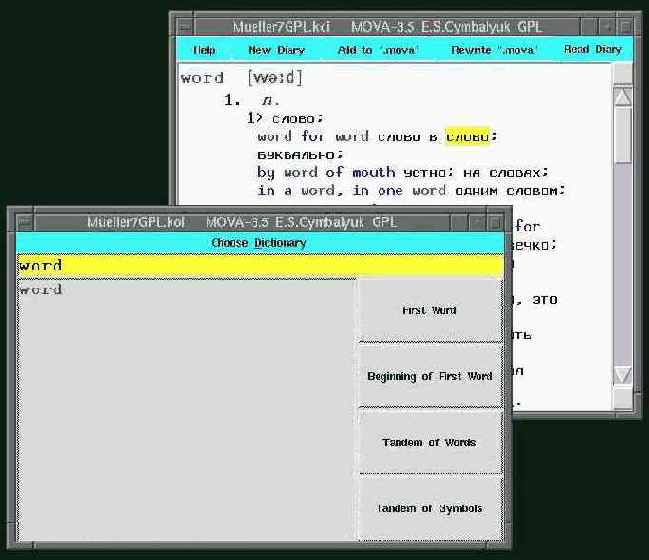
Dictionary - выбор активного словаря. Открыть меню можно щелчком мышки или нажатием Alt-d
New Diary - при нажатии на эту клавишу слово отмеченное мышкой становится именем текущего Diary файла.
Add to Diary - добавляет содержимое окна вывода словарной статьи в конец текущего файла Diary.
Rewrite Diary - сохраняет текст в окне вывода словарной статьи в текущем файле Diary (по умолчанию это .mova) в домашнем каталоге пользователя. Предыдущее содержимое этого файла будет уничтожено.
Read Diary - можно выбрать Diary для вывода в окно. Открыть меню можно щелчком мышки или нажатием Alt-r
В директории DIR/share/mova/icons/ находятся иконки, специально сделанные для данного пакета, поместите их в директорию используемую windows manager для хранения иконок. mova_22x15.xpm; mova_32_22.xpm; mova_48x32 - для movaTK, а mova_22x22.xpm; mova_32_32.xpm; mova_48x48 - для
movaMTK. См. screenshot
Вы можете скачать последнию версию (версия 4.0) скриптов на www.chat.ru/~mueller_dic/script_mova.tgz или www.geocities.com/mueller_dic/script_mova.tgz.
20.7.99 Дмитрий Мищенко предупреждает пользователей FreeBSD, что команда fmt имеет в ней другие ключи (изменения должны быть внесены в mova: "fmt -s -w 45" нужно заменить на "fmt 45".
6.10.99 Игорь Готс предлагает возможность сохранения всех переведенных за день слов в специальном log файле. Для этого в файле mova замените:
&/g'|fmt -s -w 45;}
на
&/g'|fmt -s -w 45|tee -a /tmp/Mueller.`date|sed 's/[ ].*//g'`.log;}
Не забудьте вычищать старые логи каждую неделю :-)
Все вопросы, замечания и предложения присылайте Евгению Цымбалюку на mueller_dic@koi.chat.ru
#bn { DISPLAY: block } #bt { DISPLAY: block }